Modelado de datos
Modelos de datos
Definición
Un modelo es un conjunto de herramientas conceptuales para describir datos, sus relaciones, su significado y sus restricciones de consistencia.
Características
- Es el proceso de analizar los aspectos de interés para una organización y la relación que tienen unos con otros.
- Resulta en el descubrimiento y documentación de los recursos de datos del negocio.
- El modelado hace la pregunta " Qué ? " en lugar de " Cómo ? ", ésta última orientada al procesamiento de los datos.
- Es una tarea difícil, bastante difícil, pero es una actividad necesaria cuya habilidad solo se adquiere con la experiencia.
Metas y beneficios
- Registrar los requerimientos de datos de un proceso de negocio.
- Dicho proceso puede ser demasiado complejo y se tendrá que crear un "enterprise data model", el cual deberá estar constituído de líneas individuales.
- Permite observar:
- Patrones de datos
- Usos potenciales de los datos
Tipos de modelado de datos
Basicamente son 3:
- Conceptual: muy general y abstracto, visión general del negocio/institución.
- Lógico: versión completa que incluye todos los detalles acerca de los datos.
- Físico: esquema que se implementara en un manejador de bases de datos (DBMS).
En las siguientes secciones se analizarán los aspectos relacionados con el modelado conceptual, más adelante y teniendo ya un modelo lógico se procederá a estudiar la representación física del mismo.
Modelado de Datos Conceptual
Conceptos básicos
Algunos aspectos a considerar al momento de realizar el modelado/análisis
- No pensar físicamente, pensar conceptualmente
- No pensar en procesos, pensar en estructura
- No pensar en navegación, pensar en términos de relaciones
Modelos conceptuales
Existen distintos tipos de modelos conceptuales:
Basados en registros
- Jerárquico: datos en registros, relacionados con apuntadores y organizados como colecciones de árboles
- Redes: datos en registros relacionados por apuntadores y organizados en gráficas arbitrarias
- Relacional: datos en tablas relacionados por el contenido de ciertas columnas
Basados en objetos
- Orientado a objetos: datos como instancias de objetos (incluyendo sus métodos)
- Entidad-relación: datos organizados en conjuntos interrelacionados de objetos (entidades) con atributos asociados
Modelo Entidad-Relación
Definición
Generalmente todo modelo tiene una representación gráfica, para el caso de datos el modelo más popular es el modelo entidad-relación o digrama E/R.
Se denomina así debido a que precisamente permite representar relaciones entre entidades (objetivo del modelado de datos).
El modelo debe estar compuesto por:
- Entidades
- Atributos
- Relaciones
- Cardinalidad
- Llaves
Conjuntos de entidades y atributos
- Entidades: todo lo que existe y es capaz de ser descrito (sustantivo).
- Atributos: es una característica (adjetivo) de una entidad que puede hacer 1 de tres cosas:
- Identificar
- Relacionar
- Describir
En el diseño se pueden considerar 3 categorías de atributosEjemplos de entidades con sus atributos
- Simples o compuestos: ya sea que el atributo sea un todo o bien este compuesto
- Color es simple, toma valores rojo, azul, etc
- Nombre es compuesto, contiene nombre de pila, apellido materno, apellido materno
- Con valores simples o multivaluados: en base a si consisten de un solo valor o un conjunto de valores.
- Telefono o Teléfonos
- Derivados: que se pueden calcular en base a otros atributos
- El promedio de préstamos se puede derivar si tenemos los valores de cada préstamo realizado a un persona
NOTA: en la práctica es mejor considerar "siempre" a todos los atributos como simples y con valores simples
Modelos tempranos
Modelo jerárquico
Modelo de red
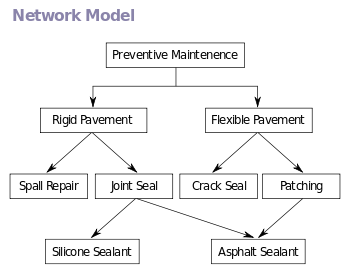 Modelo en red
Modelo en red
Modelo de fichero invertido
Modelo relacional
Artículo principal: Modelo relacional
- el orden de los atributos es irrelevante
- no puede haber tuplas repetidas
- cada atributo sólo puede tener un valor.
Modelo dimensional

{kind=link}
Estos modelos que se describen a continuación fueron populares en las décadas 1960-1970, pero hoy en día se encuentran sólo en sistemas heredados. Se caracterizan principalmente por tener características de navegación con fuertes conexiones entre la estructura física y la lógica, y poseen alta dependencia en los datos.

En un modelo jerárquico, los datos están organizados en una estructura arbórea (dibujada como árbol invertido o raíz), lo que implica que cada registro sólo tiene un padre. Las estructuras jerárquicas fueron usadas extensamente en los primeros sistemas de gestión de datos de unidad central, como el Sistema IMS por IBM, y ahora se usan para describir la estructura de documentos XML. Esta estructura permite relaciones 1:N entre los datos, y es muy eficiente para describir muchas relaciones del mundo real: tablas de contenido, ordenamiento de párrafos y cualquier tipo de información anidada.
Sin embargo, la estructura jerárquica es ineficiente para ciertas operaciones de base de datos cuando el camino completo no se incluye en cada registro. Una limitación del modelo jerárquico es su incapacidad para representar de manera eficiente la redundancia en datos.
En la relación Padre-hijo: El hijo sólo puede tener un padre pero un padre puede tener múltiples hijos. Los padres e hijos están unidos por enlaces. Todo nodo tendrá una lista de enlaces a sus hijos.
El modelo de red expande la estructura jerárquica, permitiendo relaciones N:N en una estructura tipo árbol que permite múltiples padres. Antes de la llegada del modelo relacional, el modelo en red era el más popular para las bases de datos. Este modelo de red (definido por la especificación CODASYL) organiza datos que usan en dos construcciones básicas, registros y conjuntos. Los registros contienen campos que puede estar organizados jerárquicamente, como en el lenguaje COBOL. Los conjuntos definen relaciones N:N entre registros: varios propietarios, varios miembros. Un registro puede ser un propietario de varios conjuntos, y miembro en cualquier número de conjuntos.
El modelo en red es una generalización del modelo jerárquico, en tanto está construido sobre el concepto de múltiples ramas (estructuras de nivel inferior) emanando de uno o varios nodos (estructuras de nivel alto), mientras el modelo se diferencia del modelo jerárquico en que las ramas pueden estar unidas a múltiples nodos. El modelo de red es capaz de representar la redundancia en datos de una manera más eficiente que en el modelo jerárquico.
Las operaciones del modelo de red se realizan por de navegación: un programa mantiene la posición actual, y navega entre registros siguiendo las relaciones entre ellos. Los registros también pueden ser localizados por valores claves.
Aunque no es una característica esencial del modelo, las bases de datos en red implementan sus relaciones mediante punteros directos al disco. Esto da una velocidad de recuperación excelente, pero penaliza las operaciones de carga y reorganización.
Entre los SGBD más populares que tienen arquitectura en red se encuentran Total e IDMS. IDMS logró una importante base de usuarios; en 1980 adoptó el modelo relacional y SQL, manteniendo además sus herramientas y lenguajes originales.
La mayoría de bases de datos orientadas a objetos (introducidas en 1990) usan el concepto de navegación para proporcionar acceso rápido entre objetos en una red. Objectivity/DB, por ejemplo, implementa 1:1, 1:N, N:1 y N:N entre distintas bases de datos. Muchas bases de datos orientadas a objetos también soportan SQL, combinando así la potencia de ambos modelos.
En un fichero invertido o de índice invertido, los datos contenidos se usan como claves en una tabla de consulta (lookup table), y los valores en la tabla se utilizan como punteros a la localización de cada instancia. Esta es también la estructura lógica de los índices de bases de datos modernas, los cuales introducen sólo el contenido de algunas columnas en esa tabla de consulta. El modelo de fichero invertido puede poner los índices en ficheros planos para acceder a sus registros de manera eficiente.
 El modelo relacional fue introducido por E.F. Codd en 19701 con el objetivo de querer hacer los SGBD más independientes de las aplicaciones. Es un modelo matemático definido en términos de lógica de predicados y teoría de conjuntos, y se han implementado con él SGBDs para mainframe, ordenadores medios y microordenadores.
Los productos referidos como base de datos relacional de hecho implementan un modelo que es sólo una aproximación al modelo matemático definido por Codd. Existen tres términos usados con profusión en el modelo relacional de bases de datos: relaciones, atributos y dominios. Una relación equivale a una tabla con filas y columnas. Las columnas de una relación se llaman con rigor atributos, y el dominio es el conjunto de valores que cada atributo puede tomar.
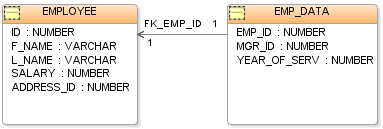
La estructura básica de datos del modelo relacional es la relación (tabla), donde la información acerca de una determinada entidad (p. ej. "empleado") se almacena en tuplas (filas), cada una con un conjunto de atributos (columnas). Las columnas de cada tabla enumeran los distintos atributos de la entidad (el nombre del "empleado", dirección y número de teléfono, p. ej.), de modo que cada tupla de la relación "empleado" representa un empleado específico guardando los datos de ese empleado concreto.
Todas las relaciones (es decir, tablas) en una base de datos relacional han de seguir unas mínimas reglas:
Una base de datos puede contener varias tablas, cada una similar al modelo plano. Una de las fortalezas del modelo relacional es que un valor de atributo coincidente en dos registros (filas) –en la misma o diferente tabla– implica una relación entre esos dos registros. Es posible también designar uno o un conjunto de atributos como "clave", que permitirá identificar de manera única una fila en una tabla.
Dicha clave que permite identificar de manera unívoca una fila en una tabla se denomina "clave primaria". Las claves son habitualmente utilizadas para combinar datos de dos o más tablas. Por ejemplo, una tabla de empleados puede contener una columna denominada "departamento"", cuyo valor coincida con la clave de una tabla denominada "departamentos". Las claves son esenciales a la hora de crear índices, que facilitan la recuperación rápidas de datos de tablas grandes. Una clave puede estar formada por cualquier columna o por una combinación de varias columnas, denominándose clave compuesta. No es necesario definir todas las claves por adelantado; una columna puede usarse como clave incluso si no estaba previsto en origen.
Una clave que tenga un significado en el mundo físico (tal como un nombre de persona, el ISBN de un libro o el número de serie de un coche) a veces se denomina clave "natural". Si no existe una clave natural viable, se puede asignar un sucedáneo arbitrario (como dar a una persona un número de empleado). En la práctica la mayor parte de las bases de datos tienen a la vez claves sucedáneas y naturales, dado que las claves sucedáneas pueden usarse internamente para crear enlaces íntegros entre filas, mientras que las claves naturales tienen un uso menos fiable a la hora de buscar o enlazar con otras bases de datos.
El lenguaje de interrogación más común utilizado con las bases de datos relacionales es el Structured Query Language (SQL).
El modelo relacional fue introducido por E.F. Codd en 19701 con el objetivo de querer hacer los SGBD más independientes de las aplicaciones. Es un modelo matemático definido en términos de lógica de predicados y teoría de conjuntos, y se han implementado con él SGBDs para mainframe, ordenadores medios y microordenadores.
Los productos referidos como base de datos relacional de hecho implementan un modelo que es sólo una aproximación al modelo matemático definido por Codd. Existen tres términos usados con profusión en el modelo relacional de bases de datos: relaciones, atributos y dominios. Una relación equivale a una tabla con filas y columnas. Las columnas de una relación se llaman con rigor atributos, y el dominio es el conjunto de valores que cada atributo puede tomar.
La estructura básica de datos del modelo relacional es la relación (tabla), donde la información acerca de una determinada entidad (p. ej. "empleado") se almacena en tuplas (filas), cada una con un conjunto de atributos (columnas). Las columnas de cada tabla enumeran los distintos atributos de la entidad (el nombre del "empleado", dirección y número de teléfono, p. ej.), de modo que cada tupla de la relación "empleado" representa un empleado específico guardando los datos de ese empleado concreto.
Todas las relaciones (es decir, tablas) en una base de datos relacional han de seguir unas mínimas reglas:
Una base de datos puede contener varias tablas, cada una similar al modelo plano. Una de las fortalezas del modelo relacional es que un valor de atributo coincidente en dos registros (filas) –en la misma o diferente tabla– implica una relación entre esos dos registros. Es posible también designar uno o un conjunto de atributos como "clave", que permitirá identificar de manera única una fila en una tabla.
Dicha clave que permite identificar de manera unívoca una fila en una tabla se denomina "clave primaria". Las claves son habitualmente utilizadas para combinar datos de dos o más tablas. Por ejemplo, una tabla de empleados puede contener una columna denominada "departamento"", cuyo valor coincida con la clave de una tabla denominada "departamentos". Las claves son esenciales a la hora de crear índices, que facilitan la recuperación rápidas de datos de tablas grandes. Una clave puede estar formada por cualquier columna o por una combinación de varias columnas, denominándose clave compuesta. No es necesario definir todas las claves por adelantado; una columna puede usarse como clave incluso si no estaba previsto en origen.
Una clave que tenga un significado en el mundo físico (tal como un nombre de persona, el ISBN de un libro o el número de serie de un coche) a veces se denomina clave "natural". Si no existe una clave natural viable, se puede asignar un sucedáneo arbitrario (como dar a una persona un número de empleado). En la práctica la mayor parte de las bases de datos tienen a la vez claves sucedáneas y naturales, dado que las claves sucedáneas pueden usarse internamente para crear enlaces íntegros entre filas, mientras que las claves naturales tienen un uso menos fiable a la hora de buscar o enlazar con otras bases de datos.
El lenguaje de interrogación más común utilizado con las bases de datos relacionales es el Structured Query Language (SQL).
.PNG) El modelo relacional fue introducido por E.F. Codd en 19701 con el objetivo de querer hacer los SGBD más independientes de las aplicaciones. Es un modelo matemático definido en términos de lógica de predicados y teoría de conjuntos, y se han implementado con él SGBDs para mainframe, ordenadores medios y microordenadores.
El modelo relacional fue introducido por E.F. Codd en 19701 con el objetivo de querer hacer los SGBD más independientes de las aplicaciones. Es un modelo matemático definido en términos de lógica de predicados y teoría de conjuntos, y se han implementado con él SGBDs para mainframe, ordenadores medios y microordenadores.
El modelo dimensional es una adaptación especializada del modelo relacional usada para almacenar datos en depósitos de datos, de modo que los datos fácilmente puedan ser extraídos usando consultas OLAP. En el modelo dimensional, una base de datos consiste en una sola tabla grande de datos que son descritos usando dimensiones y medidas. Una dimensión proporciona el contexto de un hecho (como quien participó, cuando y donde pasó, y su tipo). Las dimensiones se toman en cuenta en la formulación de las consultas para agrupar hechos que están relacionados. Las dimensiones tienden a ser discretas y son a menudo jerárquicas; por ejemplo, la ubicación podría incluir el edificio, el estado y el país. Una medida es una cantidad que describe el dato, tal como los ingresos. Es importante que las medidas puedan ser agregados significativamente -por ejemplo, los ingresos provenientes de diferentes lugares puedan sumarse.
En una consulta OLAP, las dimensiones y los hechos son agrupados y añadidos juntos para crear un informe. El modelo dimensional a menudo es puesto en práctica sobre el modelo relacional usando un esquema de estrella, consistiendo en una tabla que contiene los datos y tablas circundantes que contienen las dimensiones. Dimensiones complicadas podrían ser representadas usando múltiples tablas, usando un esquema de copo de nieve.
Un almacén de datos (data warehouse) puede contener múltiples esquemas de estrella que comparten tablas de dimensión, permitiéndoles ser usadas juntas. El establecimiento de un conjunto de dimensiones estándar es una parte importante del modelado dimensional.
Llaves
- Super llave: conjunto de uno o más atributos que "juntos" identifican de manera única a una entidad
- Llave candidata: es una super llave mínima
- Llave primaria: la seleccionada para identificar a los elementos de un conjunto de entidades.
Ejemplo:
Teniendo los atributos de la entidad "persona"
| Nombre | Dirección | Teléfono | CURP |
- Las superllaves serían:
- Nombre y Dirección
- Nombre y CURP
- CURP
- Las llaves candidatas serían
- Nombre y Dirección
- CURP
- La llave primaria sería
- CURP
Categorías de atributos
NOTA: como se mencionó anteriormente NO es lo mejor el emplear estos atributosEjemplos de atributos derivados, compuestos y multivaluados
Entidades débiles
- Una entidad débil es aquella que no posee una llave primaria
- Para existir dependen de una relación con una entidad fuerte
- Pueden contener algun atributo "discriminante" que podría considerarse como aquel que lo distingue pero no de manera única, de ahí que no se considere como llave
Guías de nombramiento
Es importante mantener guías o reglas para poder tener una documentación uniforme y consistente de todos los datos.
- Entidades: una sola palabra (en singular) y con mayúsculas
- Atributos:
- FirstName
- first_name
- de relacion: VendorID, ProductName
- Valores: definir que valores son válidos (NULL no es un valor)
Cardinalidades
En base al número de instancias involucradas en cada relación, éstas presentan un cardinalidad, que puede ser:
|
Múltiples relaciones entre 2 entidadesRelaciones (a)uno-muchos, (b)muchos-uno,(c) uno-uno
Es posible mantener muchas relaciones entre las mismas entidades, inclusive con distintas cardinalidades siempre y cuando cada una represente algo totalmente independiente de las otras. No se puede asumir que las relaciones se complementan o ni mucho menos que compartan atributos.
Especialización y generalización
Es el principio de "herencia"
Las entidades de bajo nivel heredan todos los atributos de las entidades de mayor nivel
- Si se considera de arriba hacia abajo se considera como especialización
- Si se considera de abajo hacia arriba se considera como generalización
Nota: es importante mencionar que las entidades de menor nivel no poseen una llave primaria, únicamente la entidad de nivel superior es la que tiene entre sus atributos dicha llave y en consecuencia la "hereda" a las entidades especializadas.Especialización y generalización
Restricciones en las generalizaciones
De pertenencia al nivel más bajo
- Definido por condición: alguna condición (inclusive atributo) en el nivel alto define si una entidad puede o no pertenercer al nivel más bajo.
- Definido por usuario: dadas ciertas condiciones basadas en el juicio de la experiencia se decide si se puede o no pertenecer a dicho nivel.
De pertenencia entre entidades en el nivel bajo
- Disjuntas (disjoint): una entidad no puede pertenecer a 2 conjuntos de entidades de dicho nivel
- Traslape (overlapping): una entidad si puede pertenercer a 2 conjuntos de entidades
Principios de diseño
Fidelidad: se debe crear siempre un modelo que satisfaga las necesidades del problema, no sirve un modelo correcto si no cumple con la realidad que se pretende representar.
Evitar redundancia: una de las ventajas del diagrama e-r es que nos permite distinguir de una manera fácil y visual todos los entes y sus relaciones, de manera que es muy fácil identificar si un atributo se esta repitiendo en varias entidades o si una relación es innecesaria.
Simplicidad: siempre hay que procurar hacer el modelo tan simple como sea posible (sin olvidar la fidelidad) de manera que sea fácil de entender, fácil de extender y fácil de implementar.
Escoger los elementos correctos: es ocasiones es difícil identificar si una relación, elemento o atributo es correcto, para ello hay que analizar en perspectiva el diagrama y, por ejemplo si se observa una entidad con solo un atributo y que únicamente presenta relaciones de 1, entonces probablemente estamos hablando de un atributo y no de una entidad.
Relaciones n-arias: Aún cuando se pueden presentar casos en los que una relación terciaria o n-aria parezca más conveniente, es mejor siempre pensar en términos de relaciones binarias únicamente. En el peor de los casos de que exista una relación n-aria forzosa, lo que se debe hacer es convertir esa relacion R en entidad E y corregir todas las relaciones que tenía R de manera que ahora esa nueva entidad se relacione con todas las entidades que anteriormente esta.
Otras notaciones
Otras notaciones
La notación mostrada en las secciones anteriores es solo una de las existentes, aún cuando todas en esencia representen el mismo concepto existen una gran variedad de simbologías y depende de cada persona el escoger aquella que más le convenga.
Notación E/R (1) Ross, (2) Bachmann, (3) Martin, (4) Chen, (5) Rumbaugh
Por otro lado, Booch con su propuesta de un lenguaje de modelado unificado "UML" (Unified Modeling Language) abarca los aspectos de "relaciones" aplicables no solo al contexto de bases de datos sino al de programación y muchos otros más.
- El modelado es la actividad más delicada e importante en la realización de una aplicación con base de datos
- Al igual que en el desarrollo de un sistema, toda modificación al esquema de base de datos debe realizarse primero en el modelo conceptual, no en el lógico ni en el físico.
- La habilidad de crear buenos modelos es una cualidad que se adquiere con la experiencia.
Excelente trabajo todo muy importante, me facilito mi tarea
ResponderEliminarEsta muy bueno
ResponderEliminarMuy buena información .me sirvio de mucho
ResponderEliminarMuy buen trabajo :)
ResponderEliminarExcelente información, ahoro conozco un poco más de los modelos de datos, gracias Sara
ResponderEliminarMuy buena información!!
ResponderEliminar